Approximating Gradients for
Differentiable Quality Diversity
in Reinforcement Learning
Bryon Tjanaka
Oral Qualification Exam, 14 April 2022
Committee
- Stefanos Nikolaidis (Chair)
- Satyandra K. Gupta
- Sven Koenig
- Haipeng Luo
- Gaurav Sukhatme
Website
https://dqd-rl.github.io

Learning robust behaviors?
Quality diversity optimization can help.

Quality Diversity (QD)

Differentiable Quality Diversity
(DQD)
Quality Diversity for Reinforcement Learning (QD-RL)

Approximating Gradients
for DQD in RL
Experiments

Results
Quality Diversity (QD)
Differentiable Quality Diversity
(DQD)Quality Diversity for Reinforcement Learning (QD-RL)
Approximating Gradients
for DQD in RLExperiments
Results










Performance: 2,300
Front: 40%
Back: 50%

QD Objective
For every output x of the measure function m, find ϕ such that m(ϕ)=x, and f(ϕ) is maximized.
Background: MAP-Elites
- Evaluate initial random solutions.
- Select solution ϕ from the archive.
- Mutate ϕ with Gaussian noise.
- Evaluate ϕ′ and insert into archive.
- Go to step 2.
Key Insight: Stepping stones
A. Cully et al. 2015, "Robots that can adapt like animals." Nature 2015.
J.-B. Mouret and J. Clune 2015, "Illuminating search spaces by mapping elites." https://arxiv.org/abs/1504.04909








Quality Diversity (QD)
Differentiable Quality Diversity
(DQD)Quality Diversity for Reinforcement Learning (QD-RL)
Approximating Gradients
for DQD in RLExperiments
Results

CMA-MEGA
Key Insight: Search by following objective and measure gradients.
Fontaine and Nikolaidis 2021, "Differentiable Quality Diversity." NeurIPS 2021 Oral.

CMA-MEGA

CMA-MEGA

CMA-MEGA
Quality Diversity (QD)
Differentiable Quality Diversity
(DQD)Quality Diversity for Reinforcement Learning (QD-RL)
Approximating Gradients
for DQD in RLExperiments
Results
Reinforcement Learning

Policy
πϕ(a∣s)
Expected Discounted Return
f(ϕ)=Eξ∼pϕ[t=0∑Tγtr(st,at)]



Policy Gradient Assisted MAP-Elites
(PGA-MAP-Elites)
O. Nilsson and A. Cully 2021. "Policy Gradient Assisted MAP-Elites." GECCO 2021.

Policy Gradient Assisted MAP-Elites
(PGA-MAP-Elites)
O. Nilsson and A. Cully 2021. "Policy Gradient Assisted MAP-Elites." GECCO 2021.

Policy Gradient Assisted MAP-Elites
(PGA-MAP-Elites)
O. Nilsson and A. Cully 2021. "Policy Gradient Assisted MAP-Elites." GECCO 2021.

Policy Gradient Assisted MAP-Elites
(PGA-MAP-Elites)
O. Nilsson and A. Cully 2021. "Policy Gradient Assisted MAP-Elites." GECCO 2021.

Policy Gradient Assisted MAP-Elites
(PGA-MAP-Elites)
O. Nilsson and A. Cully 2021. "Policy Gradient Assisted MAP-Elites." GECCO 2021.

Inspired by
PGA-MAP-Elites!
Quality Diversity (QD)
Differentiable Quality Diversity
(DQD)Quality Diversity for Reinforcement Learning (QD-RL)
Approximating Gradients
for DQD in RLExperiments
Results
Hypothesis:
Since CMA-MEGA performs well in DQD domains,
it will outperform existing QD-RL algorithms
(i.e. PGA-MAP-Elites and MAP-Elites).
| DQD | QD-RL |
|---|---|
Exact Gradients  | |
CMA-MEGA | CMA-MEGA? |
Problem: Environments are non-differentiable!

Solution: Approximate ∇f and ∇m.
| DQD | QD-RL |
|---|---|
Exact Gradients | Approximate Gradients |
CMA-MEGA | CMA-MEGA with |
Approximating ∇f
↑
Expected discounted return
Off-Policy Actor-Critic Method (TD3)



S. Fujimoto et al. 2018, "Addressing Function Approximation error in Actor-Critic Methods." ICML 2018.




Evolution Strategy (OpenAI-ES)
Salimans et al. 2017, "Evolution Strategies as a Scalable Alternative to Reinforcement Learning" https://arxiv.org/abs/1703.03864
Evolution Strategy (OpenAI-ES)

Approximating ∇m
↑
Black Box
| CMA-MEGA (ES) | CMA-MEGA (TD3, ES) | |
|---|---|---|
| ∇f |  ES ES |  TD3 TD3 |
| ∇m | ES | ES |
CMA-MEGA (ES) & CMA-MEGA (TD3, ES)

CMA-MEGA (ES) & CMA-MEGA (TD3, ES)

CMA-MEGA (ES) & CMA-MEGA (TD3, ES)

CMA-MEGA (ES) & CMA-MEGA (TD3, ES)

CMA-MEGA (ES) & CMA-MEGA (TD3, ES)

CMA-MEGA (ES) & CMA-MEGA (TD3, ES)
Quality Diversity (QD)
Differentiable Quality Diversity
(DQD)Quality Diversity for Reinforcement Learning (QD-RL)
Approximating Gradients
for DQD in RLExperiments
Results
QDGym
- Objective: Walk forward
- Measures: Foot contact time

QD Ant

QD Half-Cheetah

QD Hopper

QD Walker
Parameters
- 1M evaluations
- Archive of 1000 cells
- 3-layer policy
Independent Variables
- Algorithm:CMA-MEGA (ES), CMA-MEGA (TD3, ES),
PGA-MAP-Elites, MAP-Elites, ME-ES - Environment:QD Ant, QD Half-Cheetah, QD Hopper, QD Walker
Dependent Variable
- QD Score
Quality Diversity (QD)
Differentiable Quality Diversity
(DQD)Quality Diversity for Reinforcement Learning (QD-RL)
Approximating Gradients
for DQD in RLExperiments
Results
QD Ant
Best
2 legs
3 legs
QD Half-Cheetah
Best
Back foot
Front foot
QD Hopper
Best
High contact
Low contact
QD Walker
Best
Favoring one foot
| CMA-MEGA (ES) | CMA-MEGA (TD3, ES) | |
|---|---|---|
| PGA-MAP-Elites | Comparable on 2/4 | Comparable on 4/4 |
| MAP-Elites | Outperforms on 4/4 | Outperforms on 4/4 |
| ME-ES | Outperforms on 3/4 | Outperforms on 4/4 |
Inspired by
PGA-MAP-Elites!
CMA-MEGA
(DQD Benchmark Domain)
Easy objective, difficult measures
CMA-MEGA (ES)
(QD Half-Cheetah)
Difficult objective, easy measures
| PGA-MAP-Elites | CMA-MEGA (ES), CMA-MEGA (TD3, ES) | |
|---|---|---|
| Objective Gradient Steps | 5,000,000 | 5,000 |
Future Directions
Future Directions
Additional Projects
pyribs
A bare-bones Python library for quality diversity optimization.

B. Tjanaka et al. 2021, "pyribs: A bare-bones Python library for quality diversity optimization." https://github.com/icaros-usc/pyribs.
Lunar Lander Tutorial
https://lunar-lander.pyribs.orgOn the Importance of Environments in
Human-Robot Collaboration
M. C. Fontaine*, Y.-C. Hsu*, Y. Zhang*, B. Tjanaka, S. Nikolaidis. "On the Importance of Environments in Human-Robot Collaboration." RSS 2021.
Potential Future Projects

Learning collaborative strategies.

QD-RL for real-world
robots.

Enhance and publish
pyribs.
Approximating Gradients for Differentiable Quality Diversity in
Reinforcement Learning
Bryon Tjanaka
Oral Qualification Exam, 14 April 2022


Quality Diversity (QD)
Differentiable Quality Diversity
(DQD)Quality Diversity for Reinforcement Learning (QD-RL)
Approximating Gradients
for DQD in RLExperiments
Results
Supplemental
DQD Benchmark
sphere(ϕ)=i=1∑n(ϕi−2.048)2 clip(ϕi)={ϕi5.12/ϕiif −5.12≤ϕi≤5.12otherwise m(ϕ)=⎝⎛i=1∑⌊2n⌋clip(ϕi),i=⌊2n⌋+1∑nclip(ϕi)⎠⎞
Fontaine et al. 2020, "Covariance Matrix Adaptation for the Rapid Illumination of Behavior Space." GECCO 2020.
DQD StyleGAN+CLIP


Fontaine and Nikolaidis 2021, "Differentiable Quality Diversity." NeurIPS 2021 Oral.
OpenAI-ES
∇f(ϕ)≈λesσ1i=1∑λesf(ϕ+σϵi)ϵi





CVT Archive
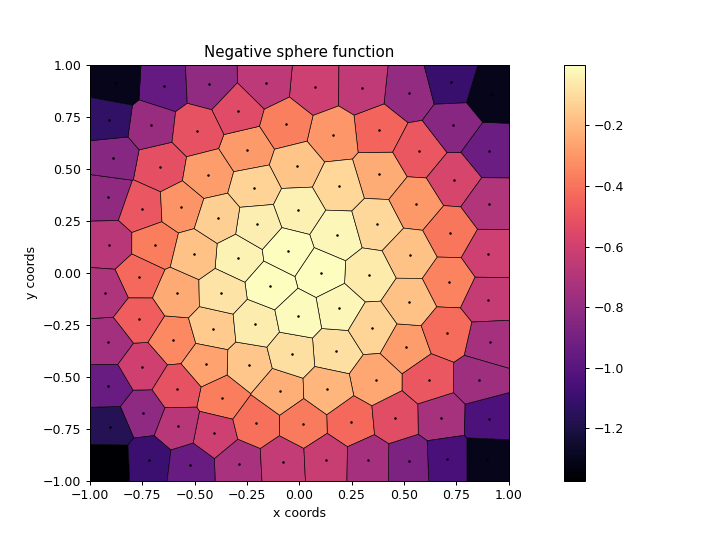
Vassiliades et al. 2018. "Using Centroidal Voronoi Tessellations to Scale Up the Multidimensional Archive of Phenotypic Elites Algorithm." IEEE Transactions on Evolutionary Computation 2018.
Sliding Boundaries Archive
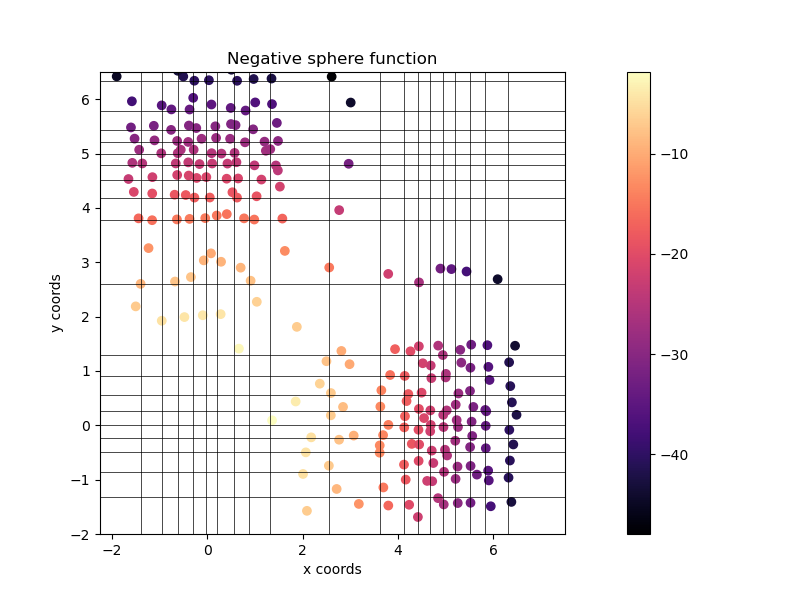
Fontaine et al. 2019. "Mapping Hearthstone Deck Spaces through MAP-Elites with Sliding Boundaries." GECCO 2019.